2024 brought unprecedented growth in CVE data, so I figured it would be appropriate to start the new year by exploring these statistics and highlighting some of the more intriguing data points.
CVEs By The Numbers
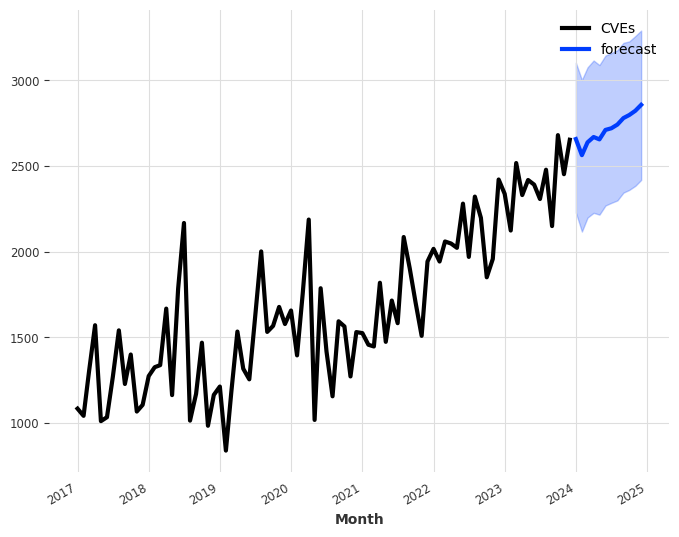
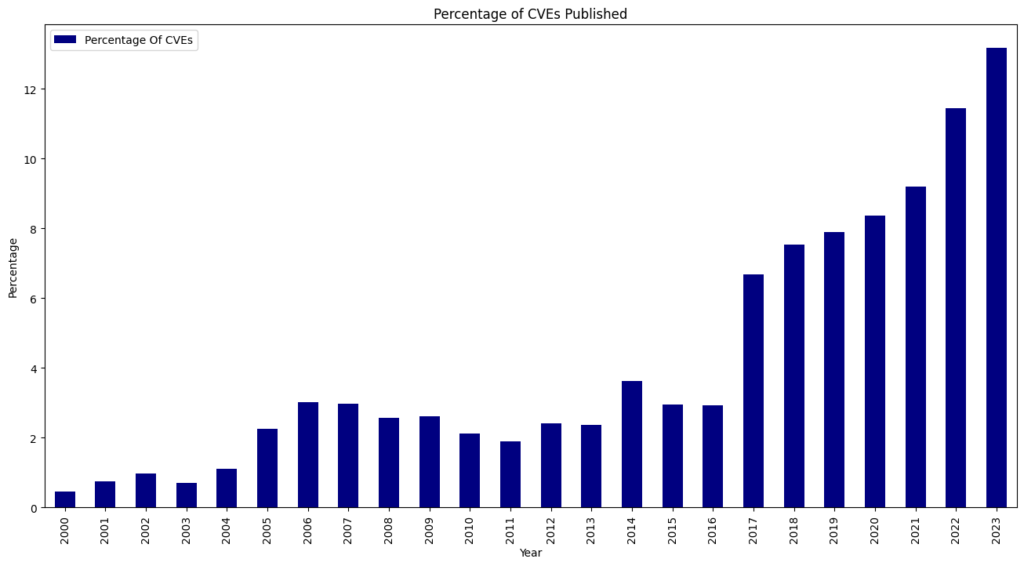
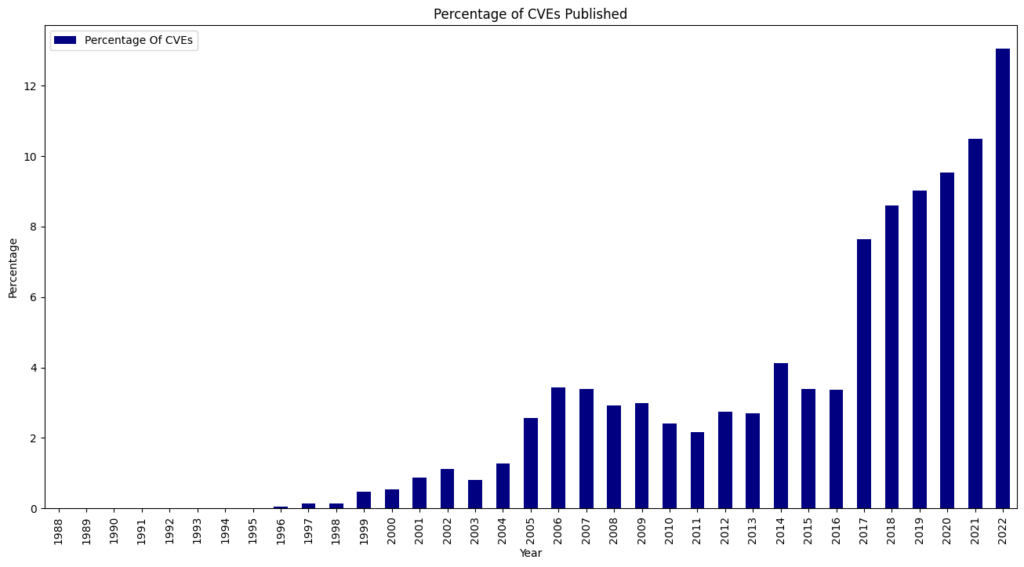
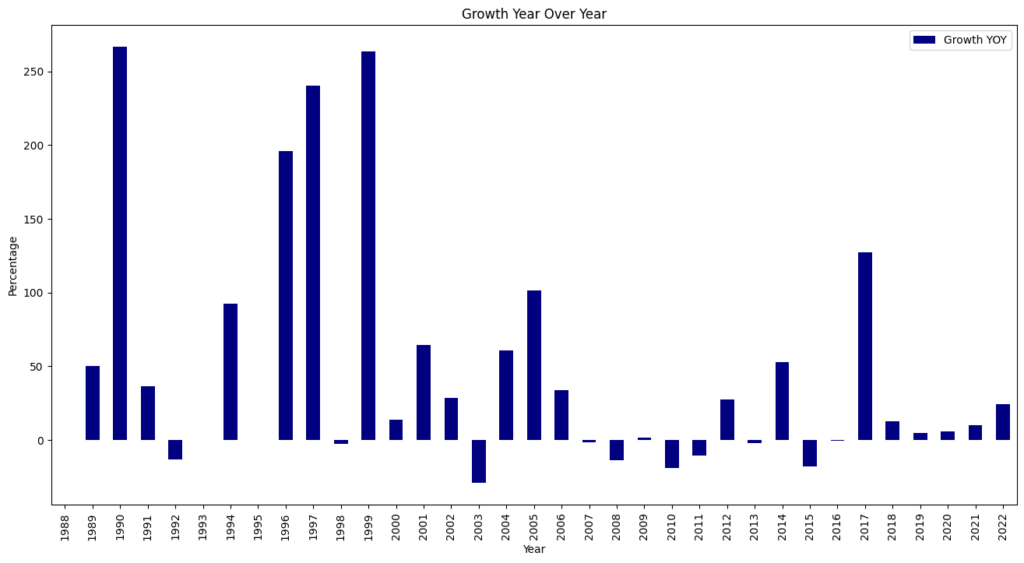
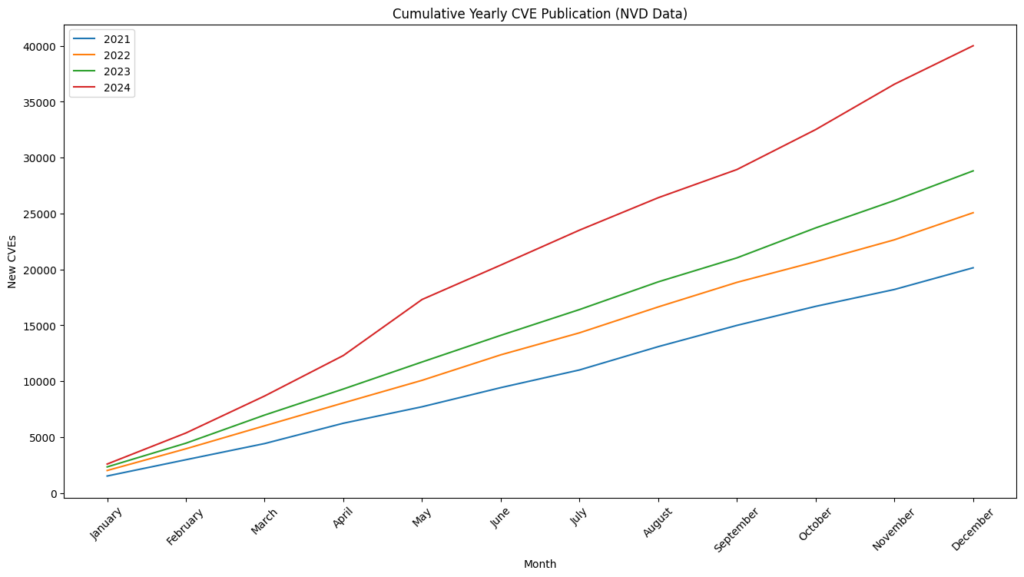
We ended 2024 with 40,009 published CVEs, up over 38% from the 28,818 CVEs published in 2023.
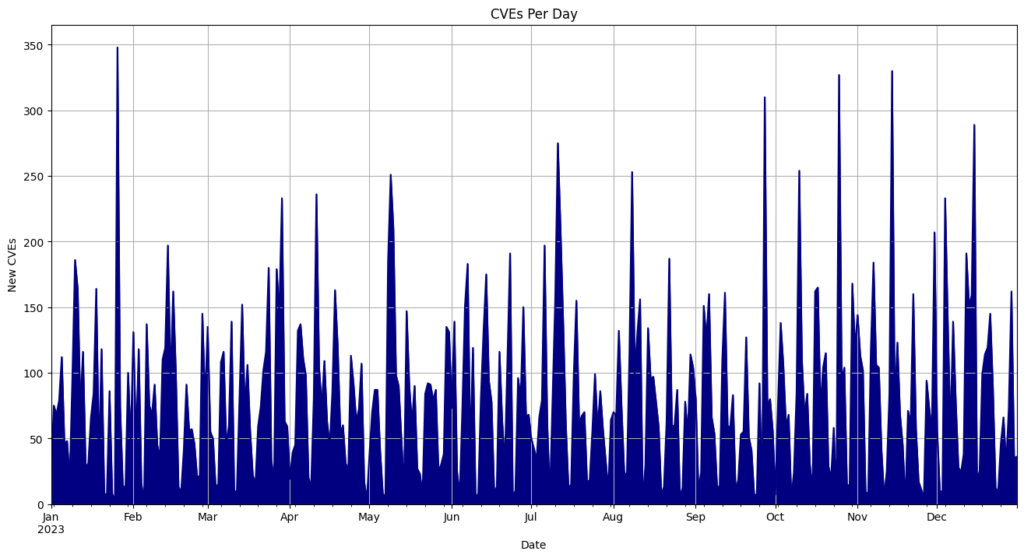
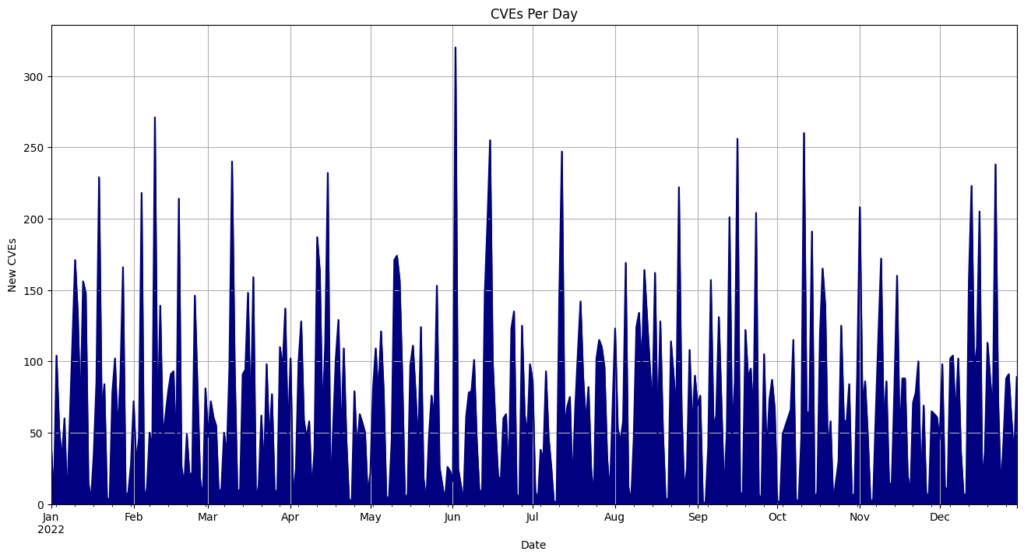
- On average, 108 CVEs were published each day.
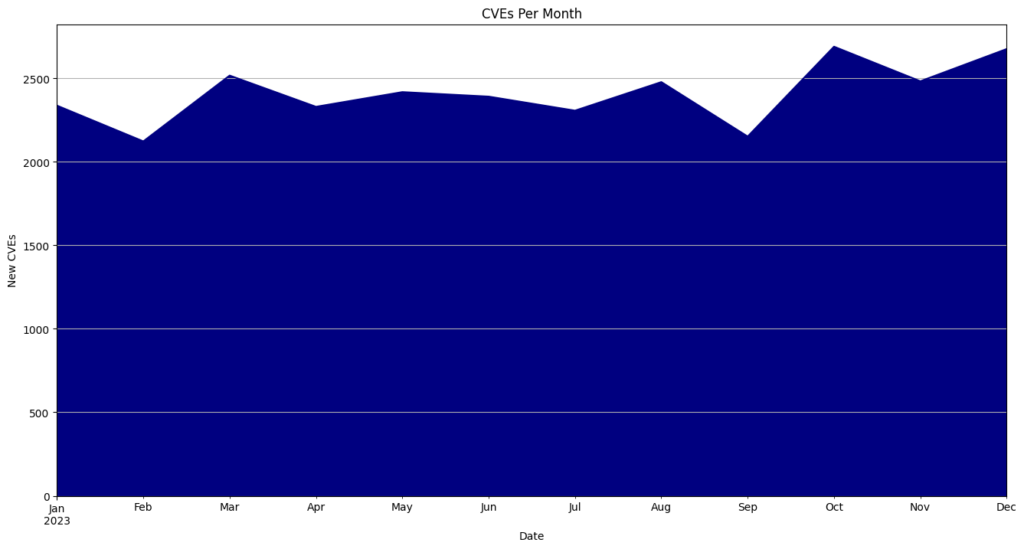
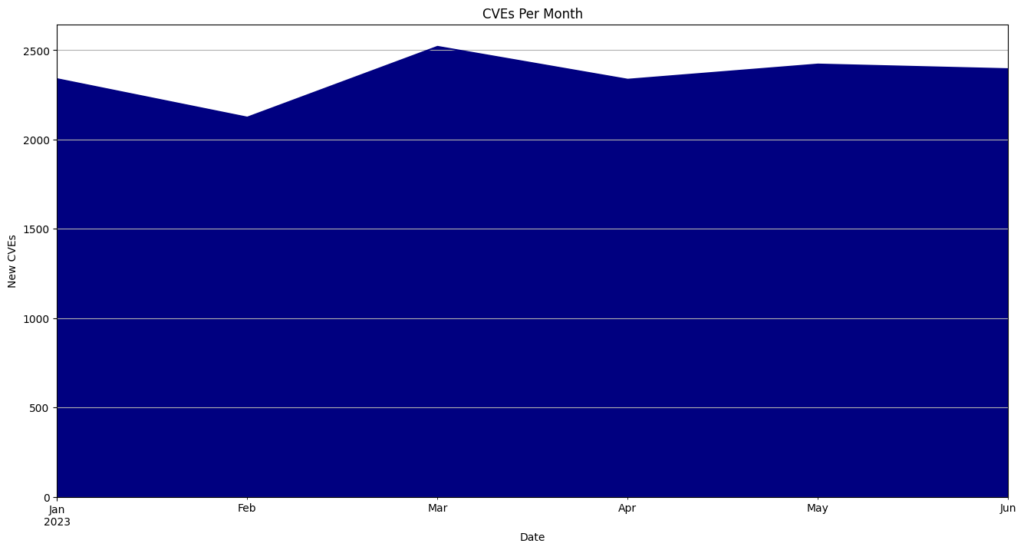
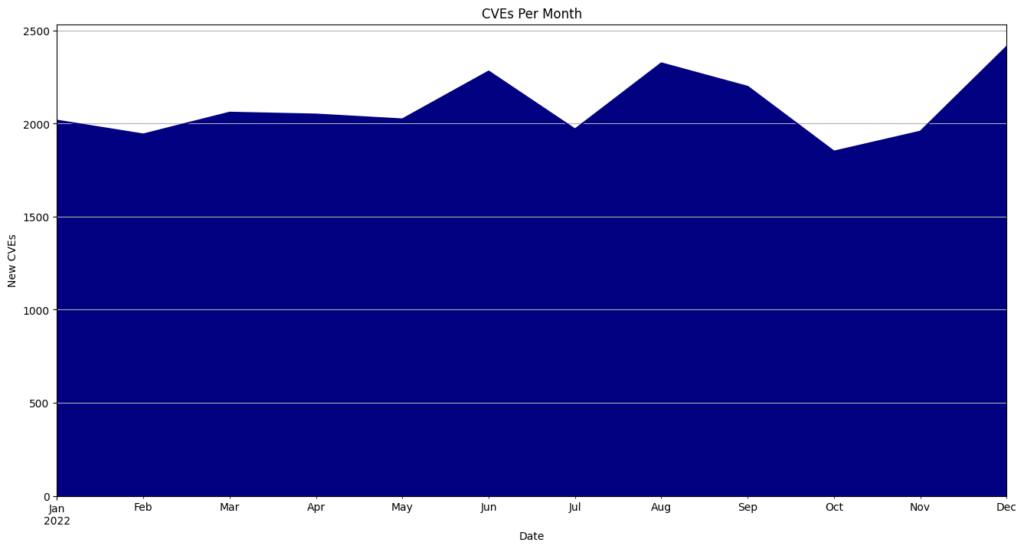
- May had the highest number of CVEs released, totaling 5,010 or 12.5% of all CVEs for the year.
- Tuesdays emerged as the leading publishing days, accounting for 9,706 CVEs, or 24.3% of published CVEs.
- May 3rd recorded the most CVEs released in a single day, with 824.
CVEs By Month
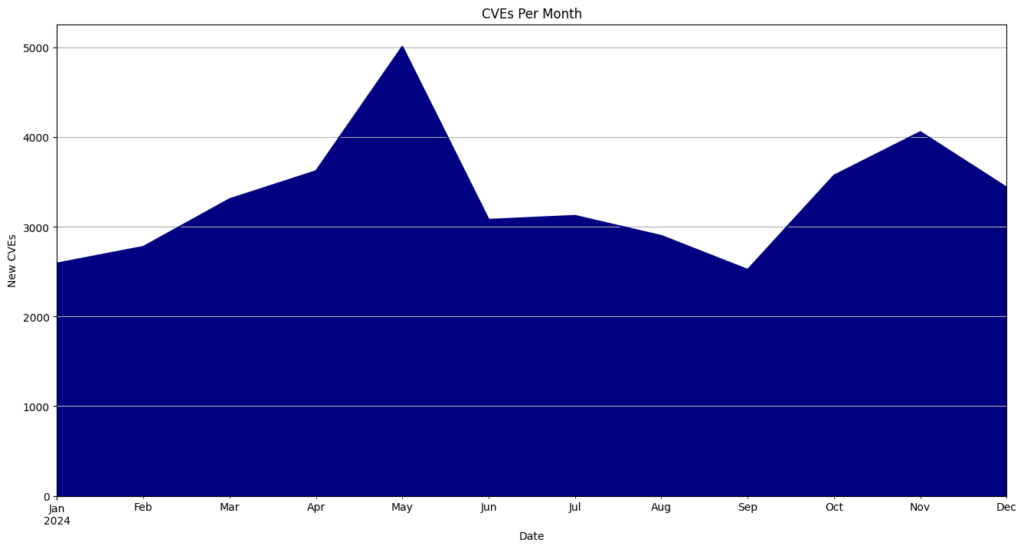
| Month | CVEs | Percentage |
|---|---|---|
| January | 2593 | 6.5 |
| February | 2778 | 6.9 |
| March | 3310 | 8.3 |
| April | 3622 | 9.1 |
| May | 5010 | 12.5 |
| June | 3080 | 7.7 |
| July | 3124 | 7.8 |
| August | 2900 | 7.2 |
| September | 2522 | 6.3 |
| October | 3573 | 8.9 |
| November | 4058 | 10.1 |
| December | 3439 | 8.6 |
CVEs By Day Of The Week
| Day | CVEs | Percentage |
|---|---|---|
| Monday | 6449 | 16.1 |
| Tuesday | 9706 | 24.3 |
| Wednesday | 7143 | 17.9 |
| Thursday | 6321 | 15.8 |
| Friday | 7100 | 17.7 |
| Saturday | 1858 | 4.6 |
| Sunday | 1432 | 3.6 |
Top 10 CVE Publishing Days
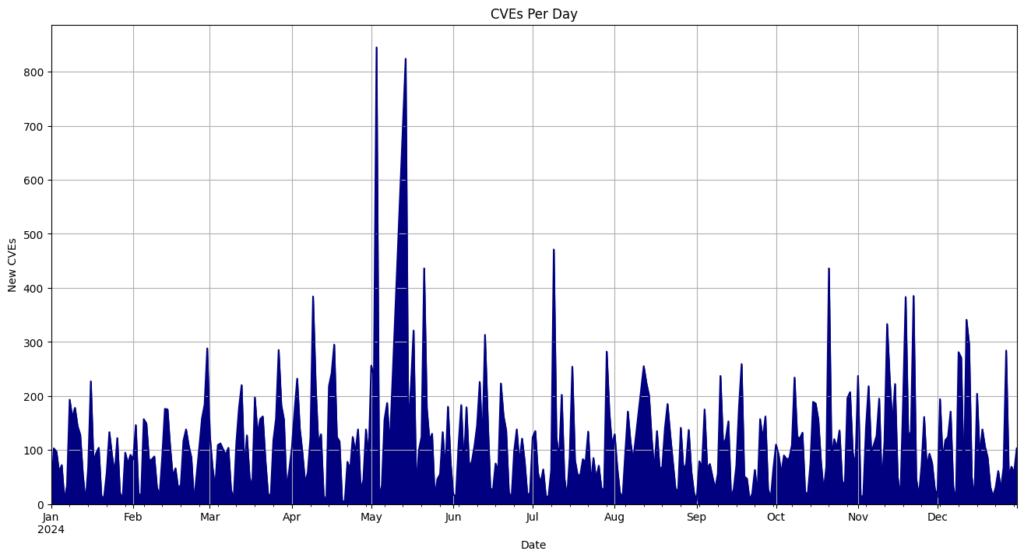
| Date | CVEs |
|---|---|
| 5/3/24 | 845 |
| 5/14/24 | 824 |
| 7/9/24 | 471 |
| 5/21/24 | 436 |
| 10/21/24 | 436 |
| 11/22/24 | 385 |
| 4/9/24 | 384 |
| 11/19/24 | 383 |
| 12/12/24 | 341 |
| 11/12/24 | 333 |
CVE Growth
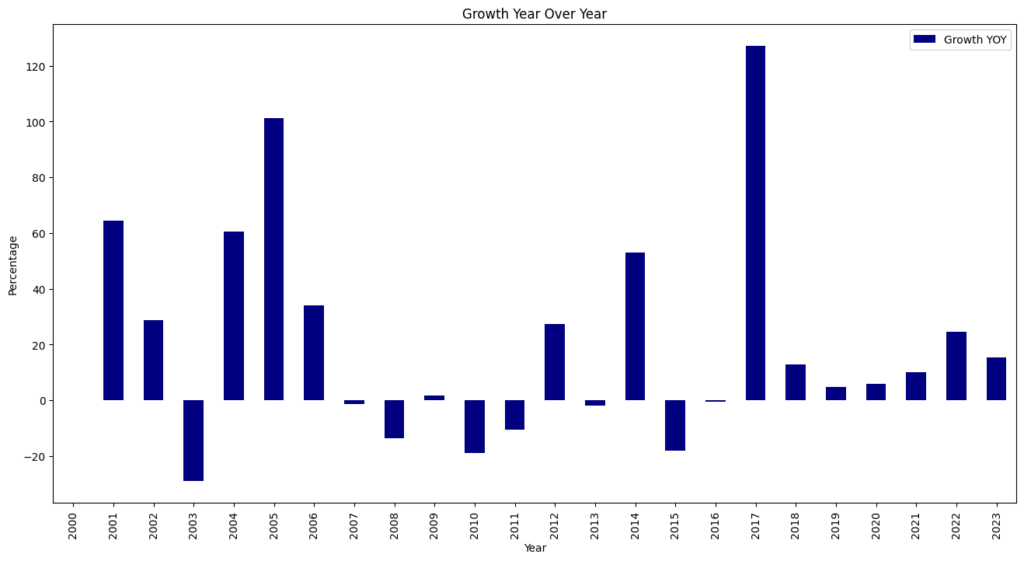
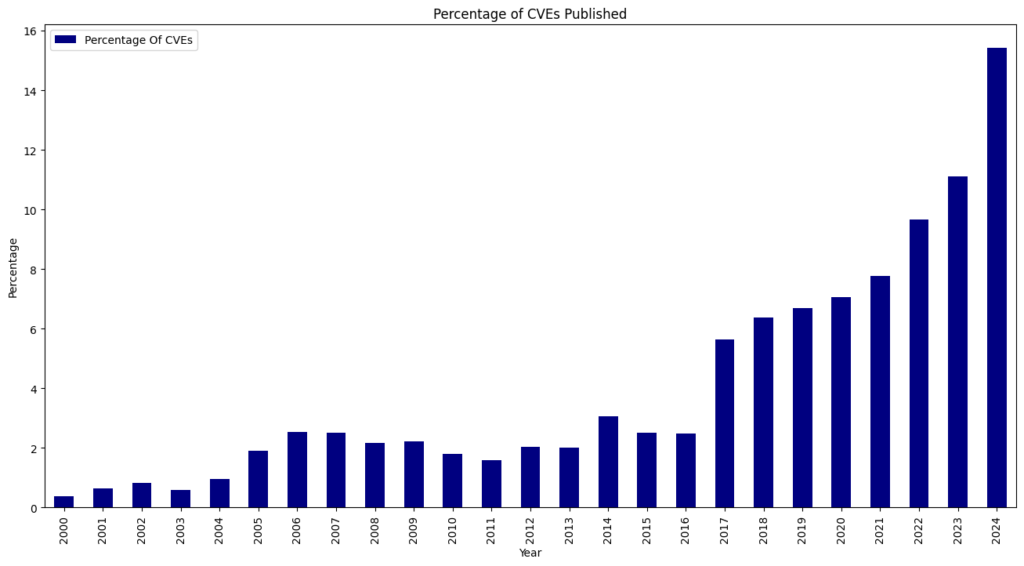
For the seventh consecutive year since 2017, we witnessed a record high of 40,009 CVEs published, marking a 38.83% increase from 2023. This means that 15.32% of all CVEs released occurred in the previous year.
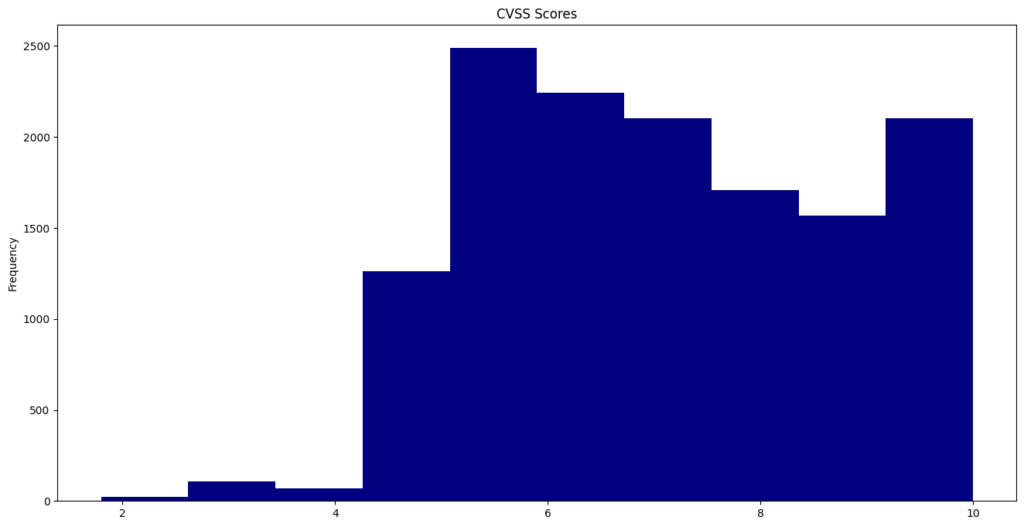
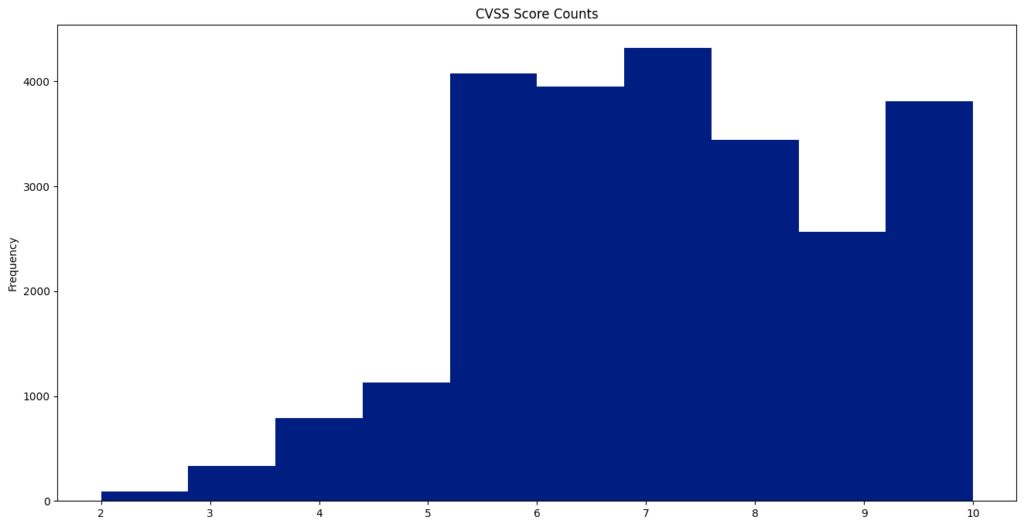
CVE CVSS Scores
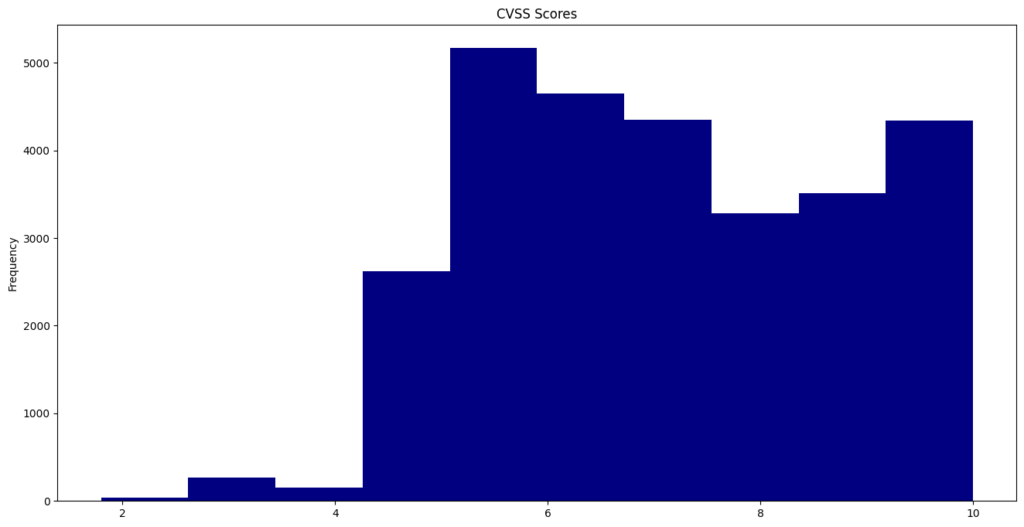
The Common Vulnerability Scoring System (CVSS) offers a way to capture the key characteristics of a vulnerability and generate a numerical score that ranges from 0.0 to 10.0, reflecting its severity. This year, the average CVSS score was 6.67.
A total of 231 vulnerabilities achieved a “perfect” score of 10.0.
CVE-2024-2365 recorded the lowest published CVSS score of 1.6.
CPE
Common Platform Enumeration (CPE) is a systematic naming convention for IT systems, software, and packages that facilitates identifying vulnerable software listed in a CVE.
This year, 19,807 distinct CPEs were recorded in CVEs, with the most prevalent being cpe:2.3:o:linux:linux_kernel:*:*:*:*:*:*:*:*, which was referenced 8,093 times.
CVE-2024-20433, related to a vulnerability in the Resource Reservation Protocol (RSVP) feature of Cisco IOS Software and Cisco IOS XE Software, has the highest number of CPEs at 2,434 unique, vulnerable configurations.
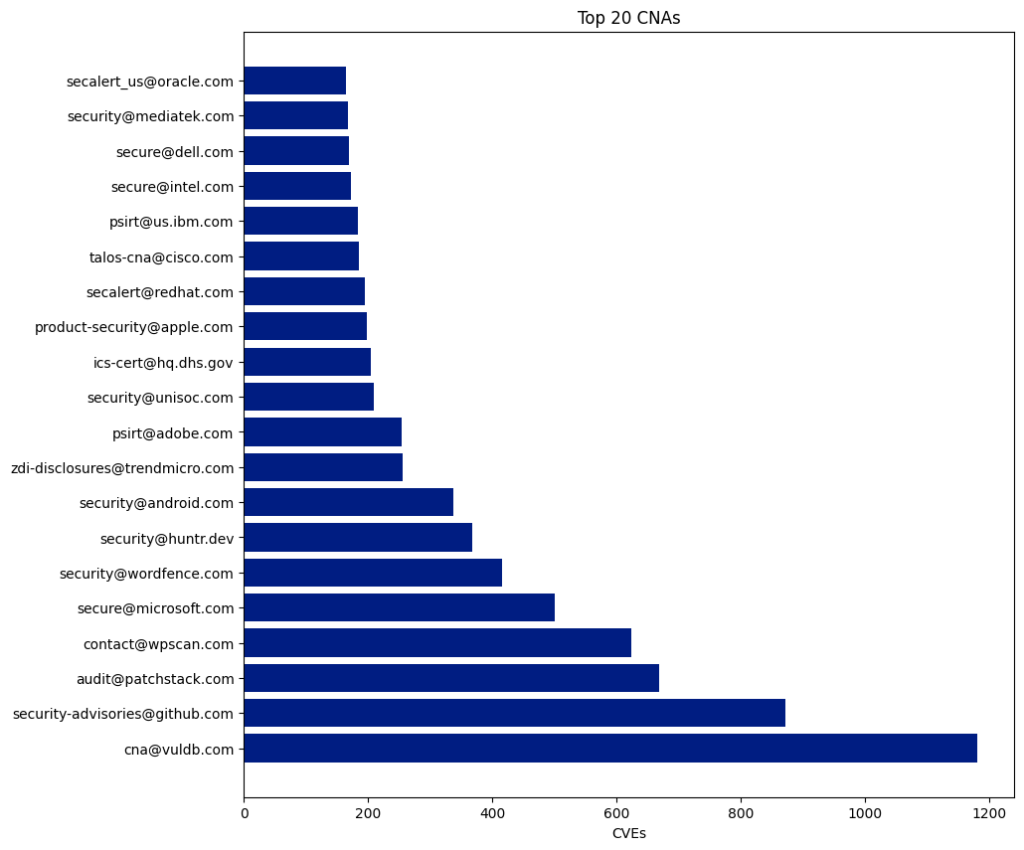
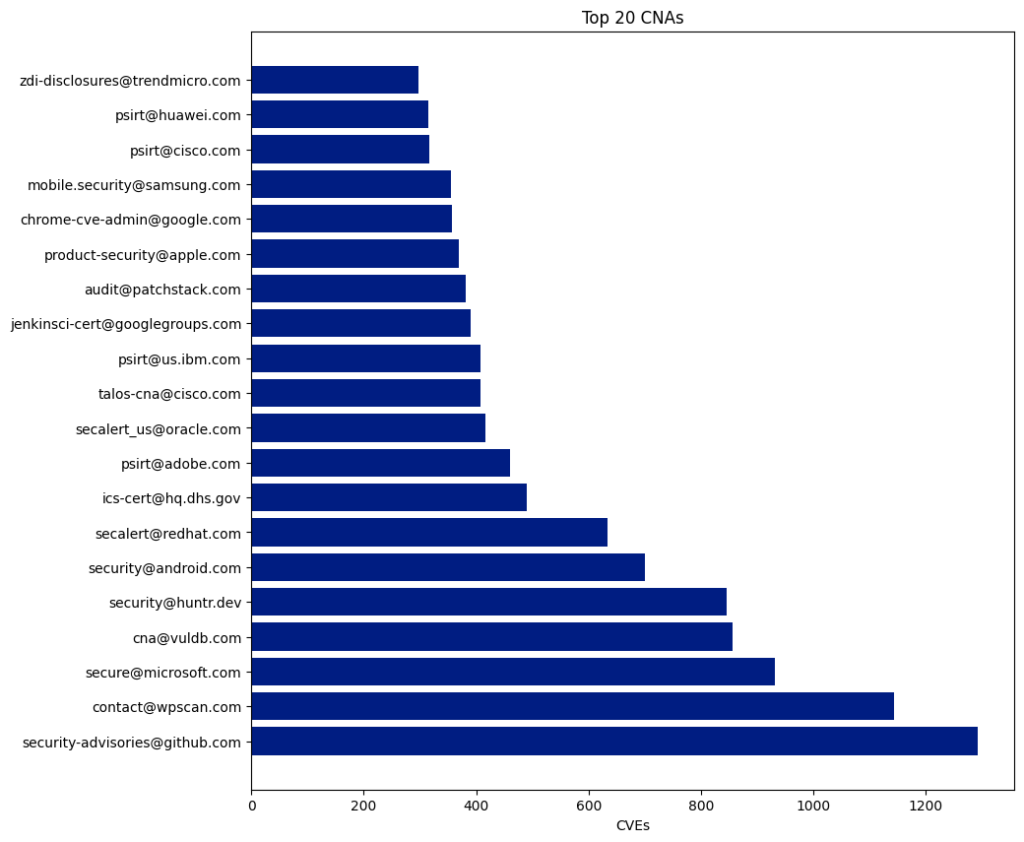
CNA
CVE Numbering Authorities (CNAs) consist of software vendors, open-source projects, coordination centers, bug bounty service providers, hosted services, and research groups that the CVE Program authorizes to assign CVE IDs to vulnerabilities and publish CVE Records within their designated scopes of coverage.
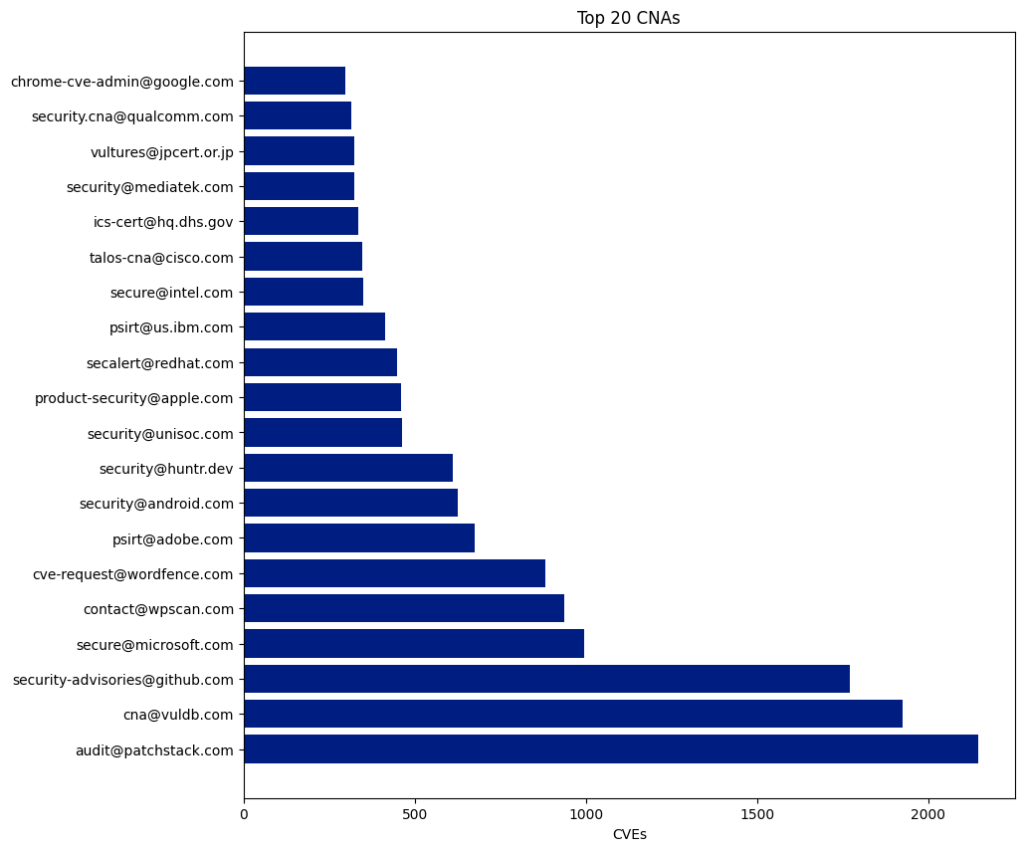
There are 433 CNAs, and 350 of them have published at least one CVE this year.
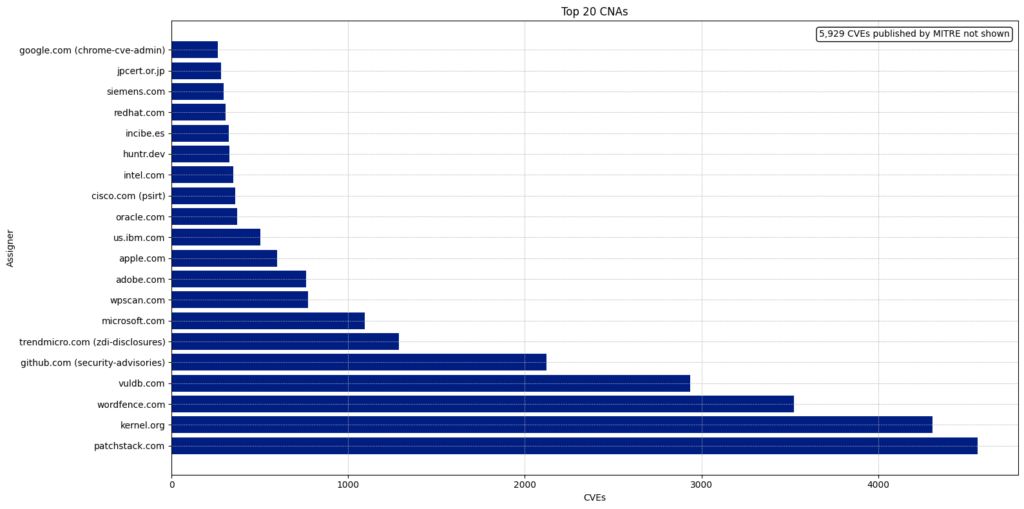
The Top 5 CNAs last year were:
| CNA | Published CVEs | Overall Percentage |
|---|---|---|
| Patchstack | 4,566 | 11.41 |
| Kernel.org | 4,325 | 10.81 |
| Wordfence | 3,525 | 8.81 |
| Vuldb | 2,936 | 7.34 |
| Github | 2,121 | 5.3 |
The top five CNAs this year were specifically established to report CVEs for open-source projects (VulDB, Kernel.org, and GitHub) or WordPress plugins (Patchstack and Wordfence). These five CNAs published 17,473 CVEs, accounting for 43.67% of all CVEs this year.
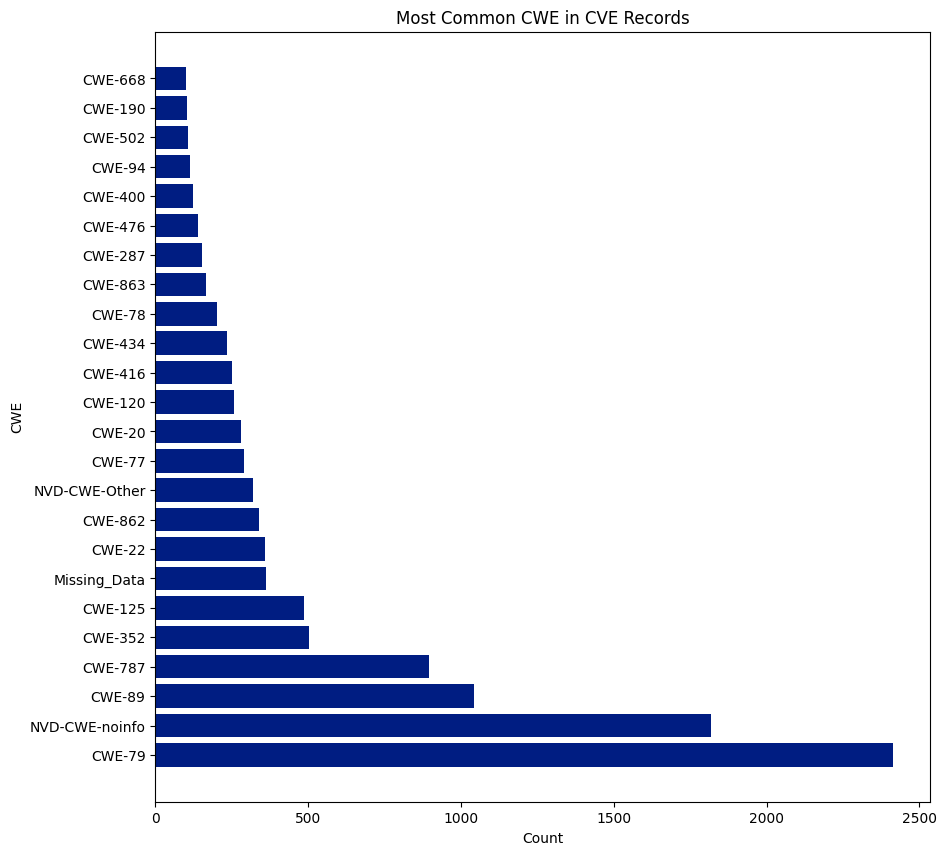
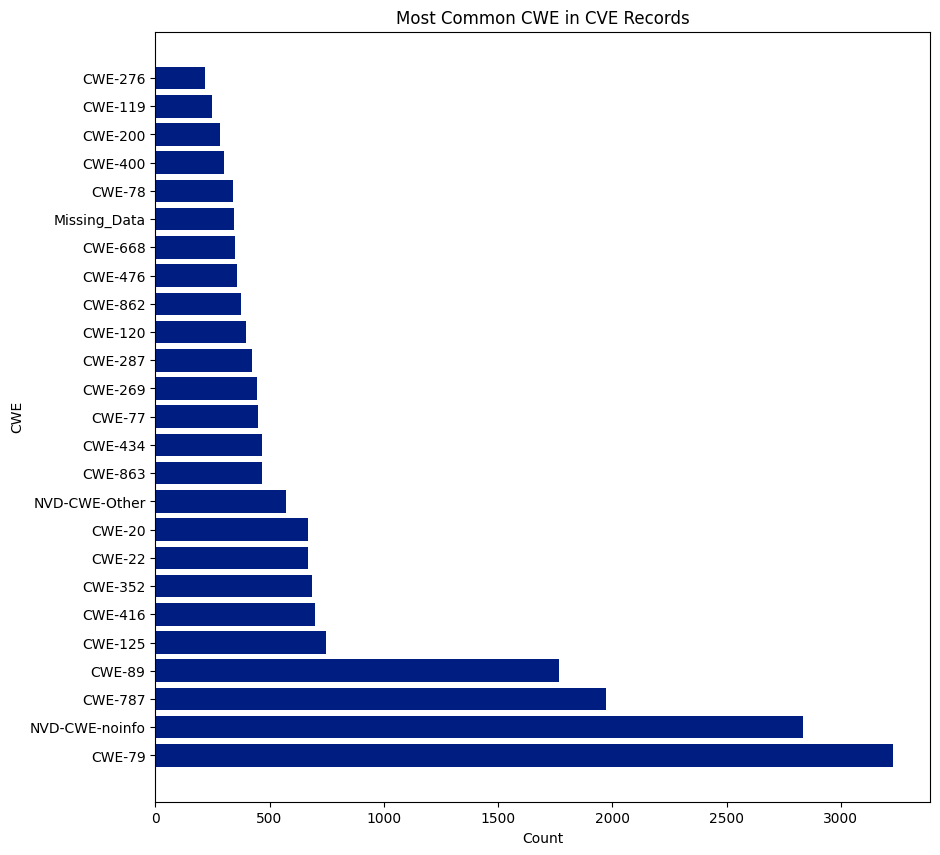
CWE
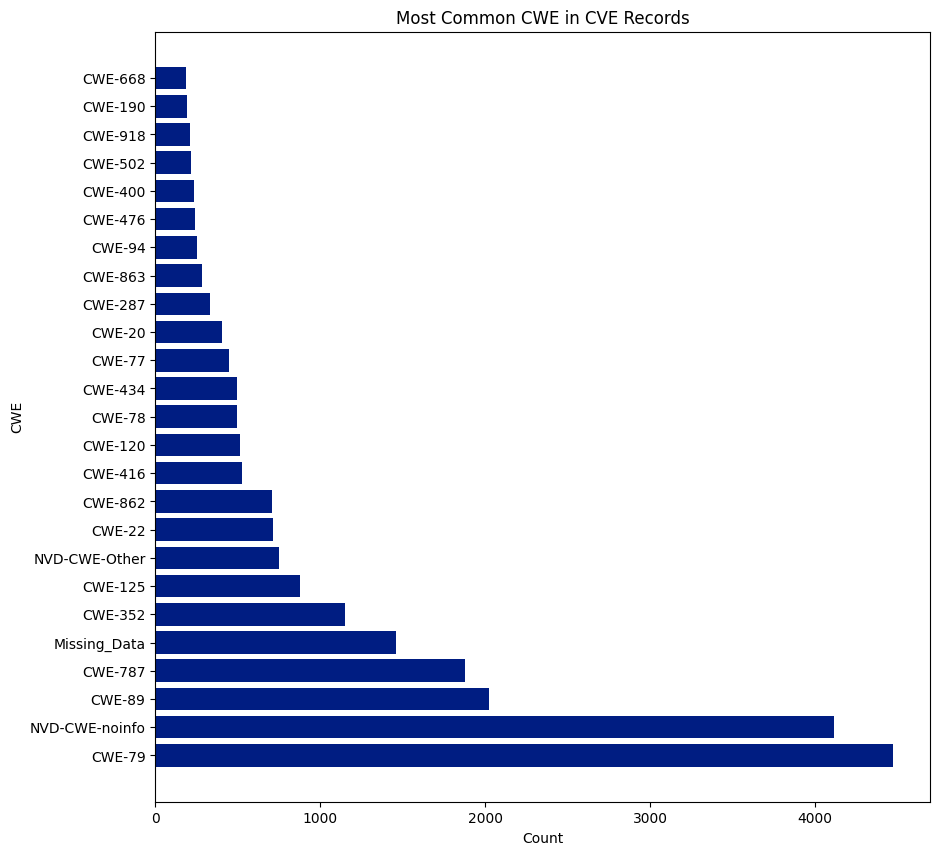
CWE is a community-developed list of software and hardware weakness types. It serves as a common language, a benchmark for security tools, and a foundation for identifying, mitigating, and preventing weaknesses.
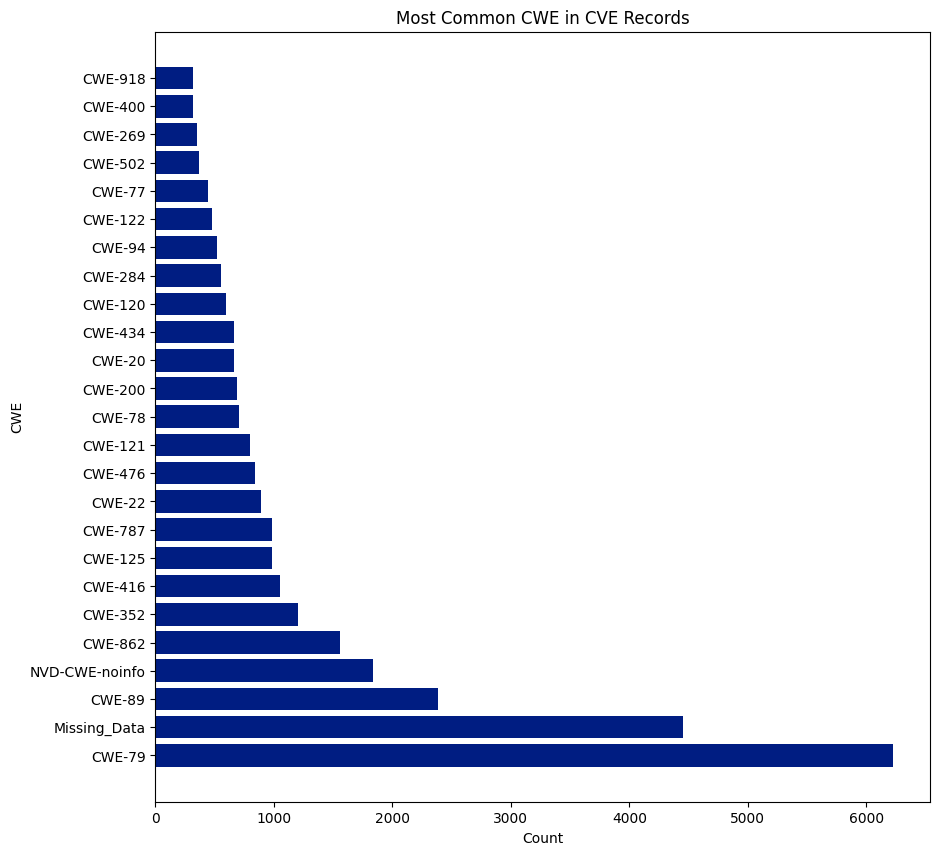
There are 940 CWEs, and 237 were assigned to CVEs this year. CWE-79 was the most assigned CWE and was assigned 6,227 times, or 15.56% of all CVEs. NVD didn’t assign a CWE (NVD-CWE-noinfo or Missing_Data) 6,292 times or 15.73% of all CVEs.
Notes
695 Rejected CVEs have been removed from the dataset this year.

This GitHub repository contains Jupyter notebooks with all the data and visualizations utilized in this blog.
CVE.ICU is an open-source project that I manage, tracking most of the aforementioned data points in real-time throughout the year, should you wish to stay updated with the data.