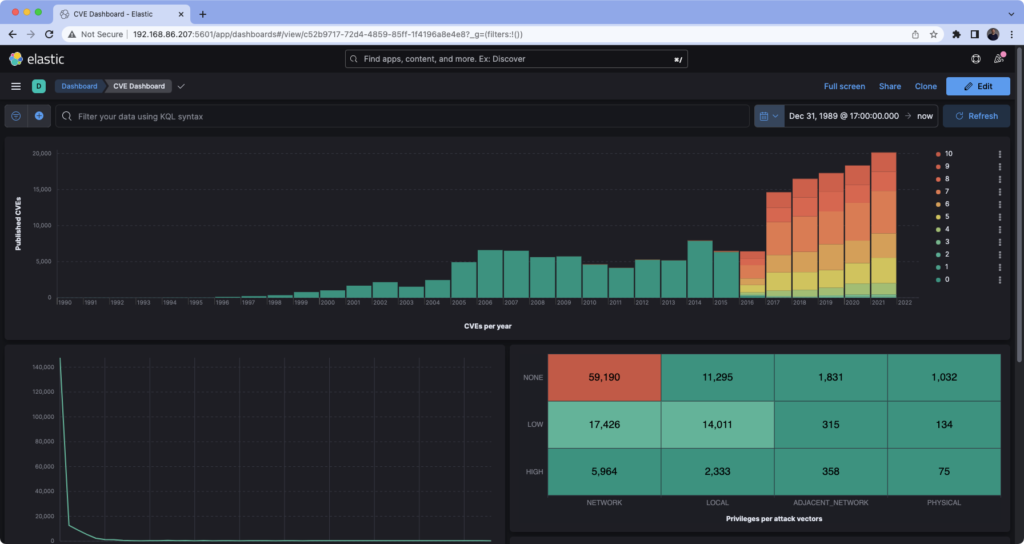
For a recent project, I needed all the NVD CVE and EPSS data in Elasticsearch and couldn’t find an easy way to do it, so I built CVElk. CVElk quickly builds a local Elastic Stack using docker compose with the help of a simple shell and python script.
Philipp Krenn from Elastic also contributed an updated dashboard to the project to help with the data visualization.
Want to Help?
The project’s code is hosted on GitHub, and I am always happy to try to implement any improvements and would love to see this become useful to a wide group of people.
While preparing for these conferences, I dug through their schedules and picked out the talks I was interested in catching.
BSides Las Vegas
BSides Las Vegas is back with a fantastic schedule and one of the best community events of the year. Here are a few fantastic talks I will try to catch.
Blackhat USA is the “commercial conference” of the three but still has a great lineup of talks. Here are the talks I will be catching (and presenting at)
Along with these talks, they have these interest-specific villages where I will spend a lot of time. Here are the villages where I know I will be spending time.
Covid restrictions are starting to be relaxed, so I am beginning to feel like Willie and am getting on the road again, and in the next six weeks, I am attending and presenting at these four amazing events.
BSidesSF is one of my favorite BSides events, from my first time in 2014 when it was held at the DNA Lounge in SOMA to recently when it moved to City View at Metreon to be closer to RSA. I am looking forward to catching up with everyone at the event.
RSA
The RSA conference has always been the start of the security conference year, and the fact it is happening in early June is going to be interesting to see how it changes the conference. I will attend and give multiple talks on CVE data and Risk Based Vulnerability Management.
CiscoLive!
I am lucky to be able to attend Cisco Live for the first to talk to our customers and attendees about Risk Based Vulnerability Management.
If you are attending any of these events, I would like to grab some time and hear what in security is interesting to you. Please ping me on Twitter or drop me an email if you will be around.
I have spent a lot of time this year working with CVE data and most of that time in Jupyter notebooks. Over the holiday season, I decided to build a website from these notebooks using Github Actions, Github Pages and NBConvert.
CVE.ICU ended up being the end product, and here is the source code. It is still an early work in progress, but please let me know if you see anything I should add.
In a Study in Scarlet, Sherlock Holmes said, “It is a capital mistake to theorize before one has data,” which is one of my favorite Sherlock quotes. For the last month or so, my team has been dealing with missing CPE data points in the Mitre CPE data, and it finally forced me to set down and put together a new tool to analyze the data.
What Are CPEs?
CPE is an acronym for Common Platform Enumeration. It is a standardized method of describing and identifying classes of applications and operating systems in a common format as described in this NIST document.
How Are They Used?
The most common use case for CPE data is fairly straightforward; you want to find all CVEs affecting either a software package or an operating system you run. The NVD actually provides an API to allow you to do these lookups programmatically.
What Are The CPE Data Quality Issues?
When a company attaches a CPE to CVE, it has four optional data points in the JSON Scheme:
VersionStartIncluding
VersionStartExcluding
VersionEndIncluding
VersionEndExcluding
These data points allow you to narrow down the version of the software that is vulnerable to the CVE.
The correct usage of these fields is present in CVE-2020-6572. Looking at the data provided, we know anything that is Chrome 81.0.4044.92 or older is vulnerable and should be patched.
The incorrect usage of this field is present in CVE-2015-8960. Looking at the data provided, we have to assume that all versions of Chrome (IE, Firefox, Safari, and Opera) are still vulnerable.
How Many CVEs Have This Problem?
As of today, 71,811 CVEs have at least one CPE that does not include version information. Not all of these are wrong, as if your CPE is mapped to a unique version, you can find an upgrade path to remove the vulnerability.
Real World Example:
To test the data, I decided to see how many CVEs with open CPE for the 3 major browsers (Chrome, Firefox, Edge) existed.
In a perfect world, Mitre and NVD would make these fields mandatory and remove the ability to assign a non-versioned CPE (ex: cpe:2.3:a:microsoft:edge:-:*:*:*:*:*:*:*) to a CVE.
Where is the Code?
The code is in this jupyter notebook and can be run on Colab:
I was recently asked if I had ever thought about trying to predict CVE growth. I had not, or really didn’t even know where to start, but after some research, I found the Prophet project that is a forecasting algorithm open-sourced by Facebook and uses the GAM family of algorithms.
Using prophet with the NVD data in a Jupyter notebook was a lot easier than I expected, and for the first iteration, I am thrilled with the outcome.
Graphs
This is the default prediction graph from Prophet. This is the default prediction graph from Prophet with change points added.
Data
Looking at the individual data points is extremely interesting. Here are the top 10 predicted days for the rest of the year, and it will be interesting to see how close the prediction is.
Date
Prediction
Prediction Low
Prediction High
2021-10-20
78.0
40.0
114.0
2021-10-13
78.0
38.0
111.0
2021-10-06
77.0
39.0
114.0
2021-10-27
75.0
38.0
113.0
2021-07-21
75.0
39.0
112.0
2021-09-29
75.0
38.0
111.0
2021-09-22
74.0
35.0
112.0
2021-10-21
74.0
37.0
108.0
2021-10-14
74.0
41.0
114.0
2021-07-28
74.0
36.0
109.0
Code
I have put the Jupyter notebook in this Github Repo and will continue to make updates and tweaks to explore time series prediction.
The first quarter of 2021 has been a busy quarter for the Project Zero (P0) team as they announced 16 “in the wild” zeros days. That is one new announcement a week on average. This is great for driving news cycles or if you’re in marketing and need some FUD to help sales. This isn’t so great if you are on a security team and have to deal with the buzz these announcements cause every week; redirecting time and resources that could otherwise be used by your team to remove the existing risk on your network.
Here is a quick breakdown of the 16 CVEs that P0 has released this year:
CVE
Product
Known Exploit
CVE-2021-1647
Microsoft Defender
TRUE
CVE-2021-1782
iOS
FALSE
CVE-2021-1870
iOS
FALSE
CVE-2021-1871
iOS
FALSE
CVE-2021-21148
Google Chrome
FALSE
CVE-2021-21017
Acrobat Reader
FALSE
CVE-2021-1732
Microsoft Windows
TRUE
CVE-2021-26855
Microsoft Exchange
TRUE
CVE-2021-26857
Microsoft Exchange
TRUE
CVE-2021-26858
Microsoft Exchange
TRUE
CVE-2021-27065
Microsoft Exchange
TRUE
CVE-2021-21166
Google Chrome
FALSE
CVE-2021-26411
Microsoft IE
FALSE
CVE-2021-21193
Google Chrome
FALSE
CVE-2021-1879
iOS
FALSE
CVE-2020-11261
Android
FALSE
Of the 16 announcements by P0, only 6 of them have publicly available proof of concept code and only the Exchange CVEs have been weaponized as far as I can tell. That means a lot of companies have spent a lot of resources rushing emergency patches out to their systems to defend against zero-days that make huge news headlines like these:
The problem is while I am sure that this is a legitimate iOS security vulnerability and P0 probably did observe one group of actors using it against another group of actors; but what risk does it pose to the average system and person on the internet?
It’s important that security teams know that they need to put out the proverbial “fire” when the “exploited in the wild” alarm is sounding. Unfortunately, a lot of these disclosures are like a fire alarm that sounds anytime there is a fire anywhere in your city versus in your actual building. If this happens too often, teams will lose faith in the “in the wild” moniker and may skip critical vulnerabilities; or alternatively, teams may exert time fixing low-risk vulnerabilities that make the headlines instead of the widely exploited vulnerabilities that are actively being used by cybercriminals.
SideBar:
Vulnerabilities likely to introduce the most likely risk to your environment are vulnerabilities that have high volume (Windows vulnerabilities) and vulnerabilities with a high velocity of exploitations (Notpetya ransomware and Mirai botnet) and should be treated differently than vulnerabilities that are low volume targeted attacks that make up the vast majority of these P0 CVEs.
To be blunt, if an exploit is being used to target a group of people by a nation-state, it should be reported, but it is not the same as a widespread automated exploit with public code and many groups exploiting it, and it shouldn’t be treated as such. Even if we added a modifier like “privately exploited in the wild” and “publically exploited in the wild” it would be easier for security teams to understand the true risk and when they need to quickly patch their systems.
Until we figure this out I am going to go reboot my iPhone because I have to protect myself from another zero-day.
That was the simple question I asked myself on Saturday morning, thinking the answer would likely be simple to find. It wasn’t and ended up 48 hours later with me building this jupyter notebook to find out.
I really thought it would be as easy as pulling down the NVD data feeds and running a simple nvd['Published'].value_counts().head(10) to find out that 1098 of 146450 CVEs were published on 2004-12-31.
I even produced a nice little graph:
Except, looking at it, that data didn’t make much sense. With some more research and help, it became clear the data quality from NVD is pretty poor.
Using a tool called MissingNo to get a visualization makes it obvious that only about half the CVEs in the data are complete:
White Space is Missing Data
When you drop CVEs that are missing the CVSS BaseScore to clean up the data here is what the new graph looks like:
The “best” answer to What Day Had The Most CVEs published appears to be 2020-04-15 with 508 of 72964 CVEs published that date.
I monitor the @CVENew Twitter feed to keep up with any interesting new vulnerabilities that are released. On December 11th CVE-2020-29589 was published claiming that “the kapacitor Docker images through 1.5.0-alpine contain a blank password for the root user” and that it has a CVSS score of 9.8.
This CVE was just a re-report of CVE-2019-5021,which I researched last year when it came out. AlpineLinux rightfully claims in their write up that “You are not affected unless you have shadow or Linux-pam packages installed.” Checking the DockerFile for the Kapactior image, it has neither package installed, so this container is not affected by either the root CVE-2019-5021 vulnerability or even the new CVE-2020-29589 it was just given. Mistakes happen, so I reached out to InfluxData to ask them to dispute the CVE and moved on with my day.
Then it started to happen. Over the last 7 days, the following CVEs were filed claiming the same issue with no verification or even attempting to reach out to the container owners to let them know a CVE was filed.
The descriptions have even started to worsen as with CVE-2020-35466, which lists the affected product as “Blackfire Docker image – store/blackfire/blackfire“, making it impossible even to check if the vulnerability exists.
With the expansion of CNAs, I know that the overall amount of CVEs will explode, with XSS bugs in specialty software like CVE-2019-14478 becoming more common. However, as long as there is some effort to verify the vulnerability, the data is still useful. If we get to the point where you can not even trust the data in a CVE is accurate, security teams’ ability to mitigate vulnerabilities becomes impossible. As Michael Roytman told me, “The only thing worse than no data is bad data,” and that is what is happening here; the CVE database is being stuffed with bad data. I have not found a way to contact the NVD or Mitre about these CVEs and am only having mixed luck letting the container owners know to dispute the CVEs.
I joined Kenna Security two years ago as their Principal Security Engineer not long after my friend JCran joined as the Head of Research. In the last two years, while building the security team, I have stayed deeply involved with the research team, and from time to time, some of that research was made public:
I always enjoyed being a practitioner and helping secure systems and software hands-on, so I had what I considered a perfect role that allowed me to do that and be as involved in research as time allowed. Then last month, JCran moved on to focus full time on intrigue.io, and it left me with a professional quandary of what my next move should.
I have always loved security research, and after initially being hesitant to move away from a practitioner role into a full-time research role, after a few discussions with Ed Bellis, it became clear that the position would be an excellent fit for my skills and a fantastic career opportunity.
With all that being said, I am happy to announce I am starting my transition to Director of Research at Kenna Security over the next few weeks.
What does that mean logistically? It means I will be 100% focused on bringing actionable data to Kenna’s customers with an admittedly blue team slant to help improve an already industry-leading product. I will also be spending a lot more time writing and releasing open source security tools and blogs. One of the most important new aspects will be talking to practitioners to understand where their vulnerability management systems are failing them and what would make their lives easier. You should expect a lot more content here, on my GitHub profile, and on KennaResearch.com as I get started.